A Glance at Netflix’s Database
Background
Since Netflix entered the streaming market in 2007, its expansion never seems to have slowed down. As of mid-2021, they have over 8,000 movie and TV series stores on their platform for over 200 million paid subscribers. It is incredible to think that Netflix was once a small company whose main business was DVD rentals since 1997. Underlying Netflix’s commercial greatness is its vast database and detailed records that support its sophisticated recommendation algorithms. This project aims to examine the basics of the Netflix database, analyze the complexity of the database, and describe the dataset in a visual language, in the hope of giving readers a grounded understanding of this popular service.
Data Source
The dataset used in this project comes from Kaggle.com. The dataset contains metadata for Netflix’s movies and TV shows, including the original release date of each title and the date it was added to Netflix and director and cast information. In addition, other variables, such as age rating, country of production, duration, and descriptions, give these titles a complete picture. This dataset collects a total of 8,807 records, essentially covering Netflix’s full database.
Inspiration
This project was inspired by Kaggle.com user Josh, who implemented visualization results through python. In Josh’s work, the visualization is used as a support tool for Exploratory Data Analysis (EDA), starting from a macro statistical overview of the entire database and gradually refining the analysis to find noteworthy points, eventually choosing the US and India as objectives for comparative analysis. Josh also places the python code used before the graphical results and includes the findings of his analysis and reflections after each outcome, giving a traceable line of thought to the article and making it easy for the reader to follow his path as one reads.
Process
Design Idea
While Josh’s article is in a very readable structure, it is more suitable as a python visualization tutorial and not very friendly to readers with no programming experience. In order to save reader‘s time and effort in gathering information, I think a dashboard would be more intuitive to convey the analysis results. In order to provide readers with the most accurate and comprehensive picture of the Netflix database, I chose the following topics for this dashboard:
- Content Type Composition
- Percentage of content by country
- Age rating distribution
- Netflix’s cast preference
- Netflix Database Expanding Trend

This plot isolates the moth from the “added_date” column to show in which month Netflix adds more content. The plot is quite eye-catching since the sectors are not evenly shaped and the top 2 sectors are high-lighted with a brighter color. However, there are no captions or legends in the graph itself. Further more, I think it would be more informative if each month statistics could be shown in the corresponding secor.
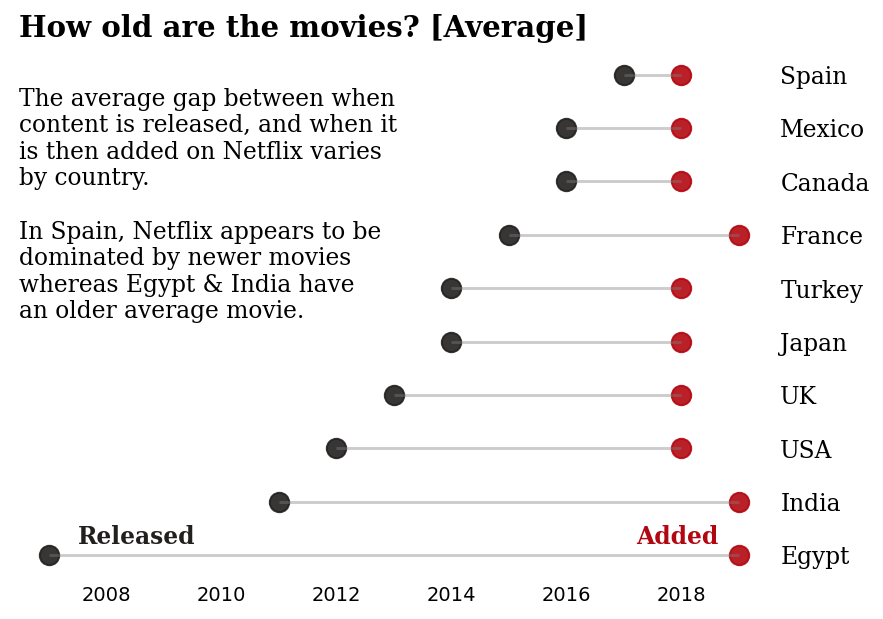
I think this graph is very well developed. The title and annotation clearly express the topic and the author’s findings. The color visually reminds the reader of the time’s order.In addition, author uses ascending order to arrange the rows makes difference noticable. Although its python code is complex, the graph is well worth referring to.
Tools Selection
Three tools were used to complete this project, each focusing on specific aspects to optimize the final presentation. These tools are R Studio, for data cleaning and exploratory data analysis; Coolors.co, for palette selection; and Tableau, for statistical analysis and data visualization.
R Studio
R Studio is an open-source integrated development environment (IDE) for R, which is an excellent programming language for statistical computing. R is also very capable of data cleaning work. Datasets cleaned with R Studio simplify the visualization process and make many complex presentations feasible.
Coolors.co
Coolors.co is a web tool that allows users with no design background to generate perfect matching colors in seconds. This tool helped the design of this project by keeping the colors of the visual charts consistent and making the final result more readable.
Tableau Public
Tableau Public is the free community version of Tableau, the world-renowned data visualization tool. With the incredible growth of data volumes, the need to process data has never been greater. Tableau’s intuitive interaction with data dramatically reduces the time and expertise threshold required to create data visualizations, enabling users with less statistical background to quickly and accurately understand data and create high-quality charts. In addition, Tableau Public allows users to upload their visualizations on the server work for presentation. This project uses Tableau Public to create and store graphs.
Data Cleaning
Since the focus of this project is on the statistics of the Netflix database, some variables in the dataset need to be modified in order to achieve the goal. Such data cleaning was performed through R Studio. The R code used is attached below for interested readers to verify.
As a result of data cleaning, columns that are not needed in the dashboard (e.g. “description”) were removed, string values that cannot be handled in Tableau (e.g. “cast” and “genre”) were separated into sub-columns, and the data format was unified to make later processing feasible. In addition, the problems of missing values and incorrect variable order that were encountered when using Tableau have also been adjusted accordingly.
# split columns
temp1 = netflix %>% separate(cast, sep = ",",c('cast1', 'cast2', 'cast3')) %>%
separate(country, sep = ",", c('country1','country2','country3','country4'), extra = "drop") %>%
separate(listed_in,sep = ",", c('genre1','genre2','genre3')) %>%
separate(director, sep = ",", c('director1','director2','director3'))
temp1$date_added =parse_date_time(temp1$date_added,orders = "mdy")
netflix2 = temp1
# fix genre order
netflix2[(netflix2$genre1 == "International TV Shows"),]$genre1 = netflix2[(netflix2$genre1 == "International TV Shows"),]$genre2
# trim elements
netflix3 = netflix2
netflix3$genre1 = str_trim(netflix3$genre1)
netflix3$country1 = str_trim(netflix3$country1)
# save cleaned datasets as csv files
write.csv(netflix2, "/Users/chenj/Desktop/SP 2022 Pratt/info658_dataVis/week6/netflix_datasets/netflix_v2.csv", row.names = T)
write.csv(netflix_movie, "/Users/chenj/Desktop/SP 2022 Pratt/info658_dataVis/week6/netflix_datasets/netflix_movie.csv", row.names = T)
write.csv(netflix_tv, "/Users/chenj/Desktop/SP 2022 Pratt/info658_dataVis/week6/netflix_datasets/netflix_tv.csv", row.names = T)
write.csv(netflix3, "/Users/chenj/Desktop/SP 2022 Pratt/info658_dataVis/week6/netflix_datasets/netflix_v3.csv", row.names = T)
Color Palette
![]()

Data visualization can be defined as the representation of numbers in shapes and colors. An effective color palette helps filter out unnecessary information distractions. The color palette used in this project is highly relevant to the topic it discusses, making it easy for users to quickly associate with Netflix and gain a deeper understanding of the data for efficient information gathering.
Visualization Results
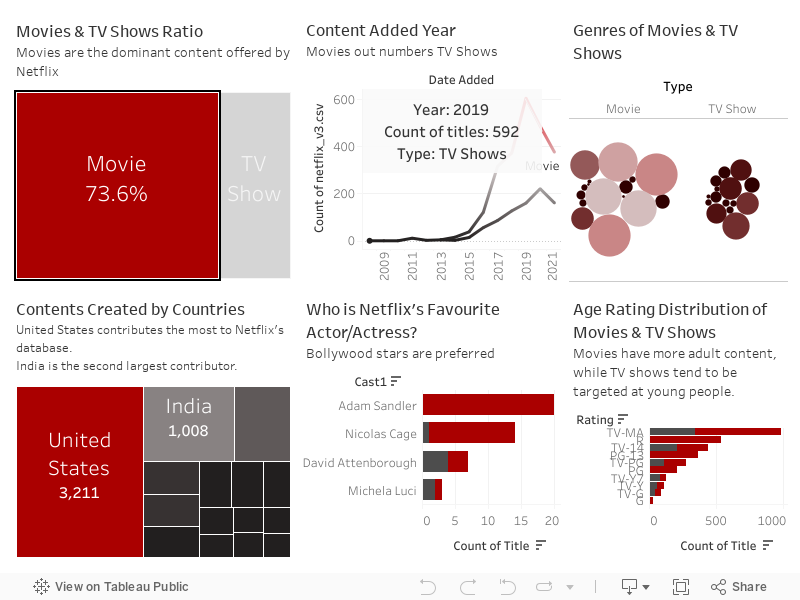
The composition of Netflix’s database is divided into Movies and TV Shows. The titles summarize the themes and findings. The colors and shapes used in the chart also mimic Netflix’s brand theme, allowing the reader to connect with the topic.
In the first plot, I used Tableau to calculate the percentage of each category and distinguished the differences with rectangular areas. I hope to use strong contrasts in color and size to make readers curious about the differences in the number of movies and TV shows and continue to find answers from the other graphs in this dashboard.
The line plot displays the number of Netflix titles by added year and shows each type in two separate lines. Annotations are made to assist readers in identifying where the gap is the greatest. This plot explains the reader’s question that arose in the previous graph, as Netflix has added more new Movies than TV shows since 2014, thus making such a big difference in its database.
Other graphs present statistics that may interest readers, such as the percentage of each genre, the number of titles produced in each country, Netflix age-graded status data, and which cast’s works Netflix includes the most. I placed the general statistics on the left and the more detailed data on the right. I think this layout matches most people’s cognitive path. I hope that readers will independently explore the connections between the data when viewing this dashboard to draw their conclusions or become more interested in exploring it more deeply. For example, while American productions make up most of the Netflix database, Bollywood actors are in more titles.
Reflection
During the process of making a dashboard with Tableau, I encountered a lot of obstacles since I am not familiar with its mechanism. I eventually solved most of the problems by modifying the data cleanup procedure, but I still have many ideas that I could not finally implement in Tableau. My future plan is to recreate the genre charts with chord plots, since the bubble plot I am using now does not show the relationships among the genres and their sub-genres. I also plan to change the age rating chart to a pyramid plot to visualize the difference between movies and TV shows more noticeably.
Acknowledgment
Thanks to Kaggle user Shivam Bansal, who collected the dataset, making this project possible. Also thanks to Josh’s data visualization project for inspiring this project.
Resources
- “Inline XBRL Viewer.” Accessed March 3, 2022. https://www.sec.gov/ix?doc=/Archives/edgar/data/1065280/000106528021000040/nflx-20201231.htm. Help Center.
- “Maturity Ratings for TV Shows and Movies on Netflix.” Accessed March 3, 2022. https://help.netflix.com/en/node/2064.
- “Netflix Data Visualization.” Accessed March 3, 2022. https://kaggle.com/joshuaswords/netflix-data-visualization.
- “Netflix EDA : With Netflix Style!” Accessed March 3, 2022. https://kaggle.com/jeongbinpark/netflix-eda-with-netflix-style.